What are deepfakes and why do we need to detect them?
Deepfakes are synthetically manipulated videos in which a person's face, voice, or both are replaced using generative AI — typically GANs or diffusion models trained on target identity footage. The result is a convincing video of someone saying or doing something they never did.
The societal consequences are severe: deepfakes have been used for political misinformation, non-consensual intimate imagery, identity fraud, and defamation. As generation quality improves and tools become accessible to non-experts, the gap between human perceptibility and machine-generated content closes rapidly — making automated detection a critical safeguard.
The core challenge is not just detecting known fakes, but generalising to unseen manipulation methods. A detector that works on one type of deepfake but fails on another provides a false sense of security. This work addresses both accuracy and generalisation.
Approach in brief
Most deepfake detectors analyse video frames independently, like a series of still images. This ignores the most telling signal: how pixels move between frames. Deepfake generators synthesise each frame plausibly in isolation, but the temporal consistency of natural motion is hard to fake — subtle inconsistencies in facial movement across time leak through.
This project exploits H.264 motion vectors — a byproduct of standard video compression that is already computed at decoding time and costs almost nothing to extract — as a temporally-aware input signal for a lightweight neural classifier. The approach was published at EI'2024.
H.264, motion vectors, and optical flow
H.264 (also known as AVC) is the most widely deployed video compression standard, used in streaming, broadcasting, and social media. Its central compression trick is temporal prediction: instead of storing every frame in full, the encoder identifies how blocks of pixels have moved since the previous (or next) frame and stores only the movement offsets — the motion vectors — plus a small residual capturing what the motion prediction missed. The decoder reconstructs the full image by warping the reference frame according to these offsets.
H.264 has three frame types. I-frames are fully intra-coded — no temporal reference — and carry no motion information. P-frames reference past frames, and B-frames reference both past and future frames (up to 16 frames away). It is from P- and B-frames that motion vectors are extracted. Within those frames, some macroblocks are still intra-coded — the encoder could not find a useful temporal prediction for them. These are called I-macroblocks, and their positions are recorded in a binary information mask (IM): a 1 means "no temporal dependency here, all information is new."
Optical flow is a different — and denser — way to represent motion. It estimates a per-pixel displacement field between two frames, capturing the apparent motion of every point in the image. RAFT (Recurrent All-Pairs Field Transforms) is the state-of-the-art deep learning model for optical flow estimation, achieving the best scores on the Sintel and KITTI benchmarks. RAFT produces much finer motion maps than H.264 motion vectors, but requires running a full neural network inference on every pair of frames — a significant computational cost.
Motion vectors are coarser (roughly 16× lower resolution than optical flow) and noisier, but they come essentially for free: they are already computed inside the video codec during normal playback. The figure below shows the visual difference between the two representations on a real and a deepfake face.
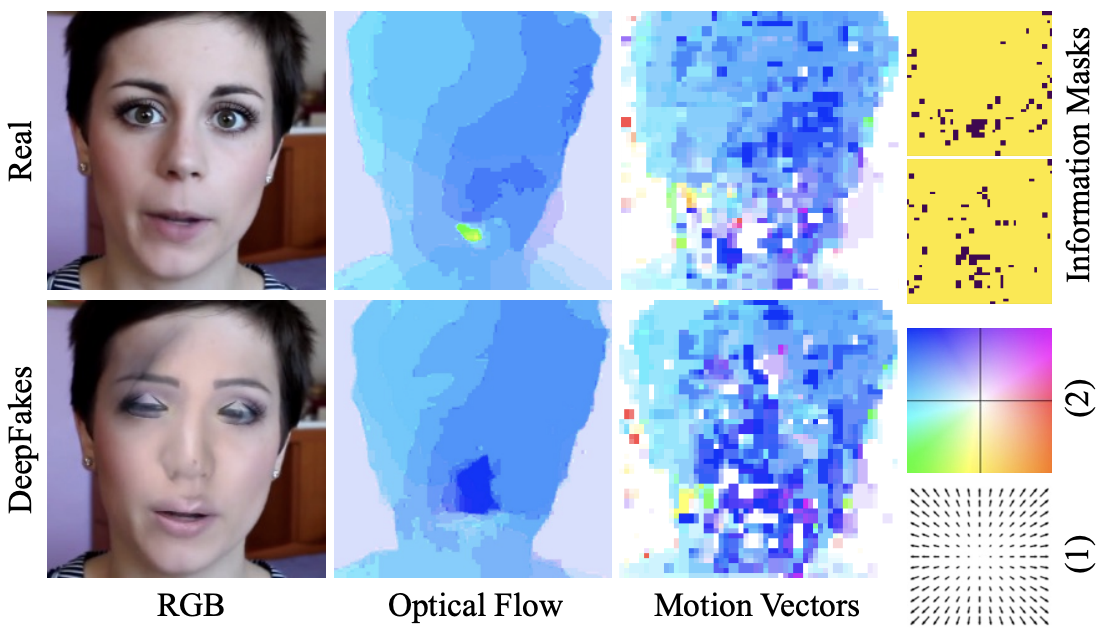
Real (top) vs. DeepFake (bottom): RGB frame, optical flow, motion vectors, and information mask. The deepfake's motion vector field is visibly noisier and less coherent — the manipulation leaves traces in the temporal domain that are invisible to the naked eye in the RGB image.
Detection pipeline
The pipeline takes a raw H.264 video file as input and outputs a fake probability in [0, 1]:
- Decoding. The H.264 bitstream is decoded frame by frame. Motion vectors and information masks are extracted directly from the codec — no full optical flow computation is needed.
- Face detection. MTCNN is applied to each frame. The largest detected face is selected and its bounding box is padded to a square and resized to 224×224.
- Cropping. The motion vector grid and information mask are cropped to the same bounding box using bi-linear and nearest-neighbour interpolation respectively, then upsampled to 224×224.
- Classification. The cropped MVs (and optionally IMs and/or RGB) are passed to a MobileNetV3 classifier. The final video prediction is the average over 100 randomly sampled frames.
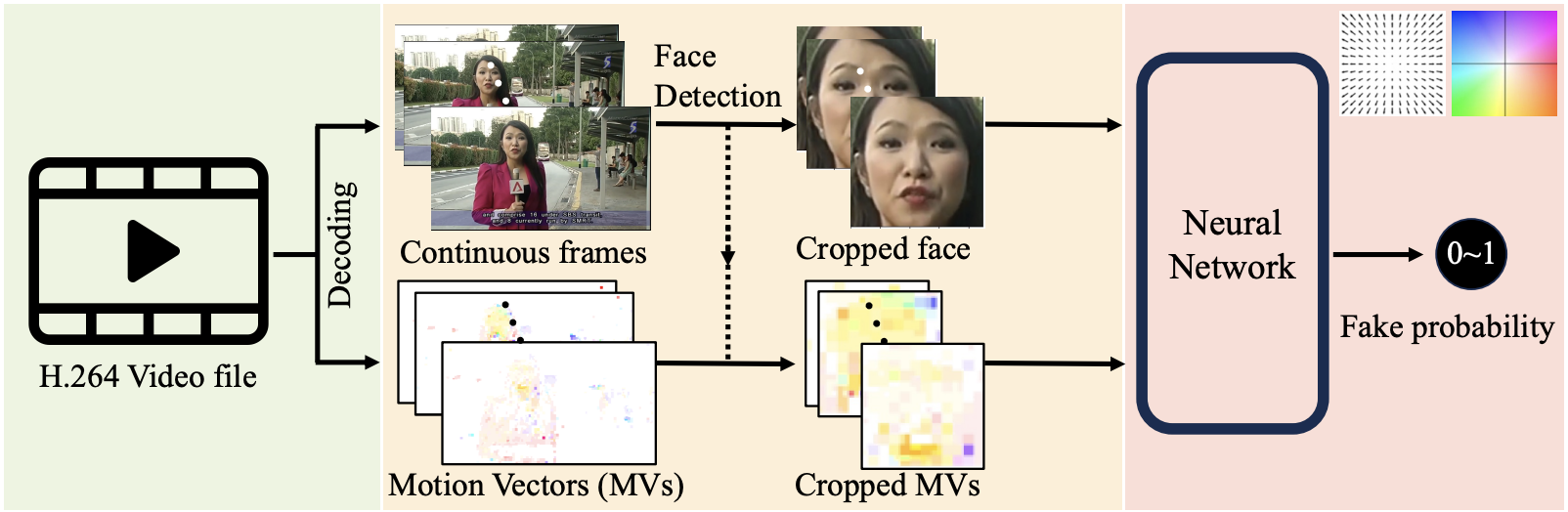
End-to-end pipeline: H.264 video → frame and motion vector extraction → face detection and cropping → neural network classifier → fake probability.
Model choice: MobileNetV3
The classifier backbone is MobileNetV3, a compact convolutional network designed via neural architecture search for low latency on mobile and edge hardware. The choice is deliberate: the central argument of the paper is that motion vectors provide a computationally cheap route to temporal awareness. Using a heavyweight backbone like EfficientNet or XceptionNet would undercut that argument.
The only architectural modification is replacing the final classification head with a single scalar output (fake probability) and adjusting the first convolution's channel count to accommodate the different input modalities — RGB (3 channels), MVs (4 channels: past-x, past-y, future-x, future-y), or MVs with IMs (6 channels). When both RGB and MVs are used, two separate MobileNetV3 branches run in parallel and their outputs are averaged.
Data augmentation: temporal awareness
Standard image augmentations — Gaussian noise, blur, JPEG compression, brightness, colour jitter — can be applied to the RGB stream without issue. But motion vectors are not images: they are 2D displacement vectors. A geometric transformation applied naively to the pixel grid must also be applied correctly in vector space.
Flips are the critical case. When a frame is horizontally flipped, every motion vector's x-component must be negated (the direction reverses), in addition to the spatial positions of all blocks being mirrored. A flip applied only to position without correcting the vector direction would produce physically impossible motion fields and corrupt the temporal signal the model is trying to learn.
GridMask is a regularisation augmentation that randomly blanks rectangular patches of the input. For motion vectors, blanked patches are set to zero (no motion) rather than a colour value, preserving the vector-space semantics.

Augmentation pipeline applied to motion vector inputs. Left to right: original, horizontal flip (x-components negated), vertical flip (y-components negated), GridMask (patches zeroed out).
Adding flips to the training pipeline yields a +1.1% accuracy gain on the in-distribution test set. More importantly, it improves the diversity of motion patterns seen during training, which contributes to cross-dataset generalisation.
Results and generalisation
The model is trained on FaceForensics++, the standard benchmark for deepfake detection, which contains five manipulation types: DeepFakes (DF), Face2Face (F2F), FaceShifter (FS), FaceSwap (FSwap), and NeuralTextures (NT), all applied to 1000 videos. Evaluation uses per-video accuracy.
In-distribution accuracy — trained and tested on FaceForensics++:
| Method | DF | F2F | FS | FSwap | NT |
|---|---|---|---|---|---|
| RAFT (optical flow) | 67.9% | 66.0% | 64.1% | 63.3% | 61.4% |
| MV only | 77.6% | 69.5% | 68.2% | 77.9% | 69.5% |
| MV + IM (ours) | 83.5% | 76.5% | 75.3% | 81.2% | 74.2% |
Adding the information mask (IM) to the motion vectors consistently improves accuracy across all forgery types — the I-macroblock map encodes where the codec gave up on temporal prediction, and in deepfakes these regions align with the synthesised facial areas.
Combining motion vectors with the RGB stream pushes accuracy above 96%, but this comes at a cost: the model overfits to the visual style of FaceForensics++ and generalises poorly to unseen datasets and forgery methods (see below).
Generalisation across forgery types
The most important evaluation is cross-forgery generalisation: train on one manipulation type, test on all others. This measures whether the detector has learned a general signature of manipulation or merely the temporal fingerprint of one specific generator. The experiment is run five times — once per forgery type — each time holding out the training type and evaluating on all remaining ones.
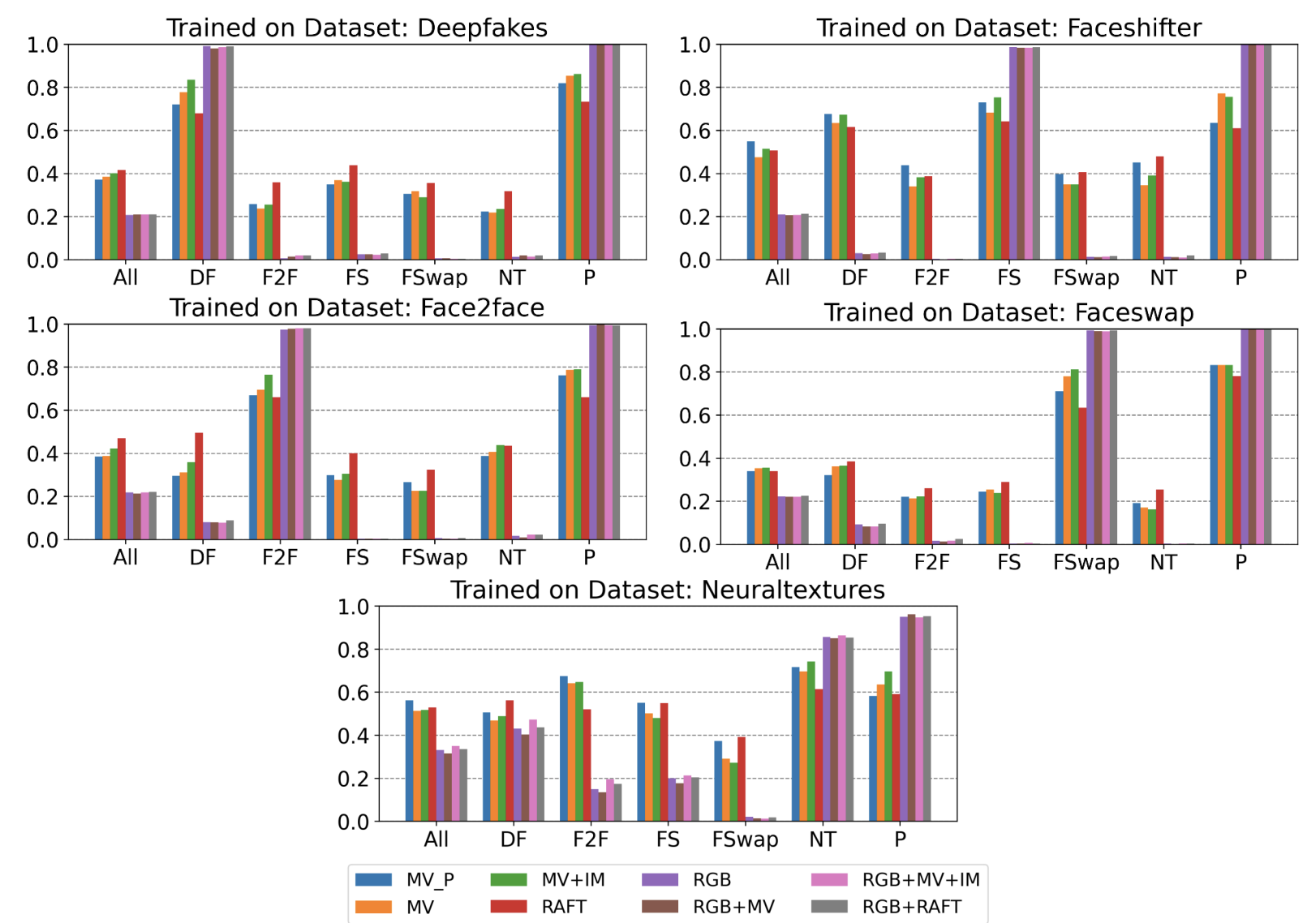
Each panel shows accuracy on all test sets when trained on a single forgery type. Bar colours correspond to input modality. RGB-based models (purple, pink) consistently reach the highest bar on the trained-on type but collapse on all others. MV+IM (orange) achieves the most balanced and stable performance across panels.
The pattern is consistent across all five panels: RGB-based models overfit immediately. They reach ~96% on the forgery type they were trained on, but drop sharply when tested on any other type — the model has memorised dataset-specific visual texture rather than learning anything about manipulation. Combining RGB with motion information (RGB+MV, RGB+MV+IM, RGB+RAFT) does not help; the RGB stream dominates and the same collapse occurs.
Motion-only models are the only configurations that transfer. Among them, MV+IM is the strongest. Averaged over all five training conditions, it achieves 63.0% cross-forgery accuracy versus 55.1% for RAFT — a +7.9 percentage point improvement using a signal that costs ~1000× less to compute. The information mask contributes meaningfully: it encodes regions where the codec's temporal predictor failed, a codec-level artefact that different generators all tend to trigger, making it a more forgery-agnostic signal than per-pixel optical flow.
Cross-forgery accuracy is not uniform. Models trained on DeepFakes generalise best (77.6% average with MV+IM), while those trained on FaceSwap or NeuralTextures generalise more narrowly — those manipulation types produce more idiosyncratic motion patterns that do not transfer as broadly. The hardest pairs are FaceSwap↔Face2Face and FaceSwap↔NeuralTextures, where accuracy drops below 30%, indicating that the motion artefacts these methods leave are largely disjoint.
Published as: Grönquist P., Ren Y., He Q., Verardo A., Süsstrunk S. "Efficient Temporally-Aware DeepFake Detection using H.264 Motion Vectors", EI'2024. arXiv:2311.10788